
转自:量子位
最近Google的Gemini Flash和OpenAI的GPT-4o等先进模型又一次推动了AI浪潮。这些模型通过整合文本、图像、音频等多种数据形式,实现了更为自然和高效的生成和交互。
北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。
该版本进一步提升了视觉自回归模型的能力,不仅在在视觉理解方面有所加强,还在图像生成和编辑任务中达到新的性能高度。
目前训练、推理和评估代码,数据,模型均已开源。

VARGPT-v1.1延续了前作的设计理念,采用了创新的“next-token”与“next-scale”自回归预测机制,同时引入四大关键创新点:
- 迭代视觉指令微调与强化学习结合的训练策略:通过交替进行监督微调(SFT)与基于偏好直接优化(DPO)的强化学习,有效提高了模型的图像生成质量。模型逐步提升图像生成分辨率,从256×256扩展至512×512像素,图像细节与真实性显著增强。
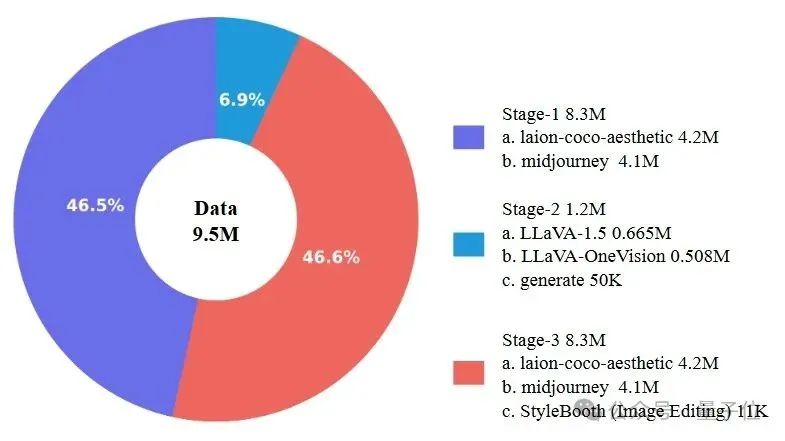
- 更大规模的视觉生成训练数据集:VARGPT-v1.1采用了多达830万条视觉生成指令数据,包括真实世界的LAION-COCO数据集以及由Midjourney与Flux模型生成的合成数据。大规模数据的使用显著扩大了模型对不同类型图像生成的泛化能力。
- 升级语言模型主干至Qwen2:引入最新的Qwen2-7B语言模型主干,利用其高效的注意力机制与更好的token化策略,有效提升了模型的视觉理解能力。
- 无架构修改的图像编辑能力:VARGPT-v1.1在不改动模型架构的基础上,通过专门构建的图像编辑数据集,实现了图像编辑功能。这使得模型不仅可以理解和生成图像,还能根据用户指令对图像进行编辑。

1 模型架构
VARGPT-v1.1 遵循 VARGPT 的模型架构设计,以统一视觉理解和生成,其架构如上图所示。由(1)一个大语言模型(Qwen2-7B)、视觉编码器和用于视觉理解的理解投影器;(2)视觉解码器和用于视觉生成的双生成投影器组成。VARGPT-v1.1在大语言模型主干中采用因果注意力机制,同时在视觉解码器中使用块因果注意力机制。
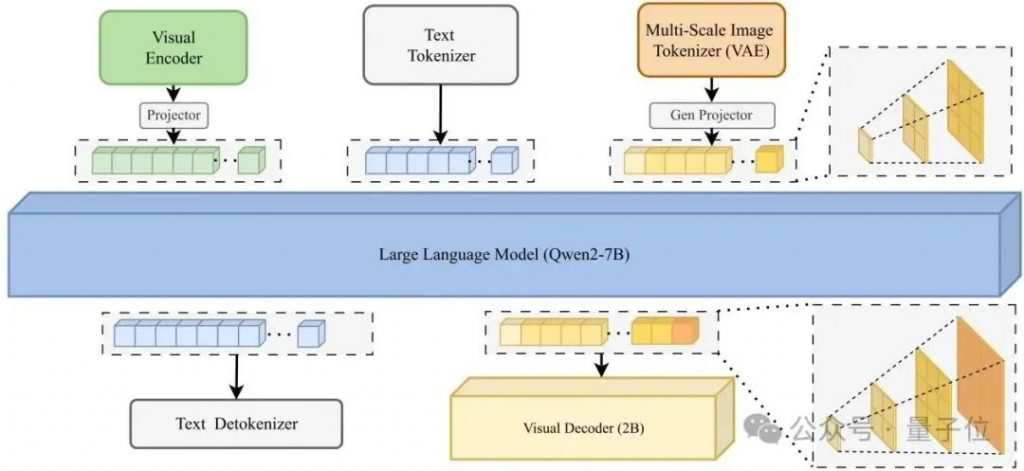
2 训练策略
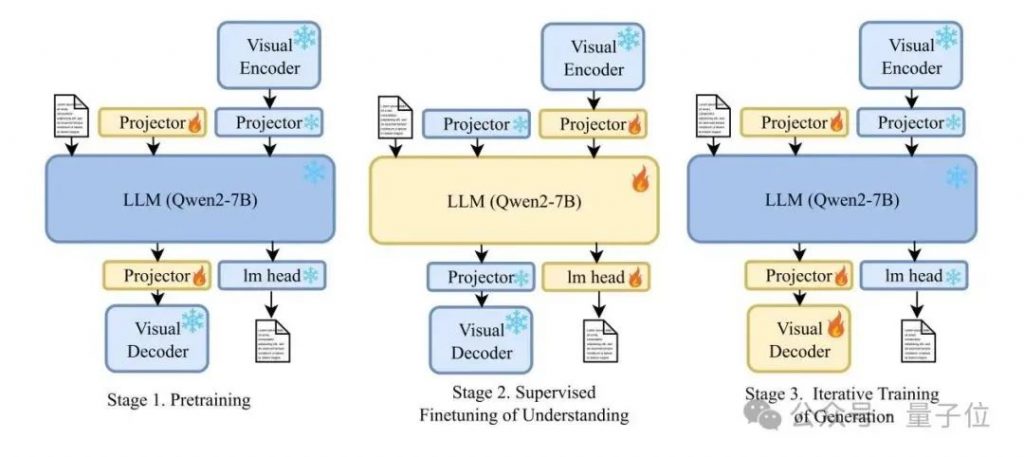
VARGPT-v1.1的训练遵循VARGPT的三阶段训练方法,整体训练过程如上图所示。区别于VARGPT,在第三阶段, VARGPT-v1.1提出了迭代指令微调和强化学习的方法,以增强统一模型的视觉生成能力。具体来说,第三阶段的迭代训练过程如下图所示:

2.1 视觉指令微调
视觉生成的指令微调旨在通过监督微调赋予VARGPT-v1.1视觉生成能力。这个阶段,首先解冻视觉解码器和两个投影器,并冻结其他参数以进行有监督微调,如上图所示。本文采用一种逐步提高图像分辨率的训练方法来训练VARGPT-v1.1。具体来说,在第一个SFT阶段,图像分辨率设置为256×256,模型训练40K步,以赋予其生成图像的初始能力。在第二个SFT阶段,图像分辨率设置为512×512 ,模型训练30K步,以进一步增强其高分辨率视觉生成能力。该视觉指令微调阶段的训练数据包括8.3M收集和构建的指令对。
2.2 基于人类反馈的强化学习
除了指令微调外,VARGPT-v1.1提出迭代指令微调与强化学习来训练视觉自回归的大视觉语言模型。VARGPT-v1.1通过将生成质量的提升表述为一个偏好选择问题,并采用直接偏好优化(DPO)来对模型进行训练。这种方法激励模型倾向于生成高质量的图像输出,同时拒绝质量较差的输出。具体来说,VARGPT-v1.1训练时将倾向于拒绝低质量的图像,接受高质量的图像来优化策略模型:
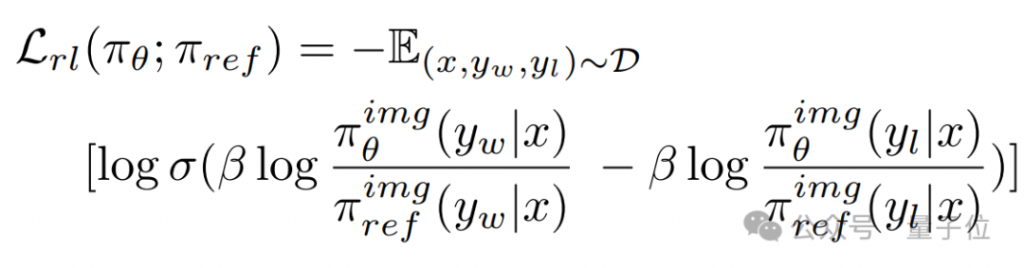
2.3 视觉编辑的有监督微调
经过有监督微调(SFT)和直接偏好优化(DPO)的多阶段渐进式分辨率迭代后,我们系统地构建了一个包含来自Style-Booth的11325个样本的指令调优数据集,以使VARGPT-v1.1具备视觉编辑能力。该流程通过视觉编码器处理目标图像,同时利用编辑指令作为文本提示,来监督模型对编辑后图像分布的逼近。这种方法实现了:(1)架构保留式适配,无需引入的冗余设计实现编辑能力;(2)通过联合文本-图像标记预测实现统一的多模态编辑。在该监督微调期间,所有模型参数均未冻结,以在保持生成多样性的同时最大化编辑保真度。
3 实验与结果
遵循VARGPT和其他多模态大语言模型的设置,本文在一系列面向学术任务的基准测试和最新的视觉理解基准测试中,评估了VARGPT-v1.1在视觉理解方面的有效性,总共涉及11个基准测试:在包括 MMMU、MME、MMBench、SEEDBench 和 POPE (包括不同的设置,随机、流行和对抗)在内的多模态基准上进行零样本多模态评估。总体来说,VARGPT-v1.1 实现了显著的视觉理解性能,在各种统一模型和各类多模态大语言模型的对比上均占优势。
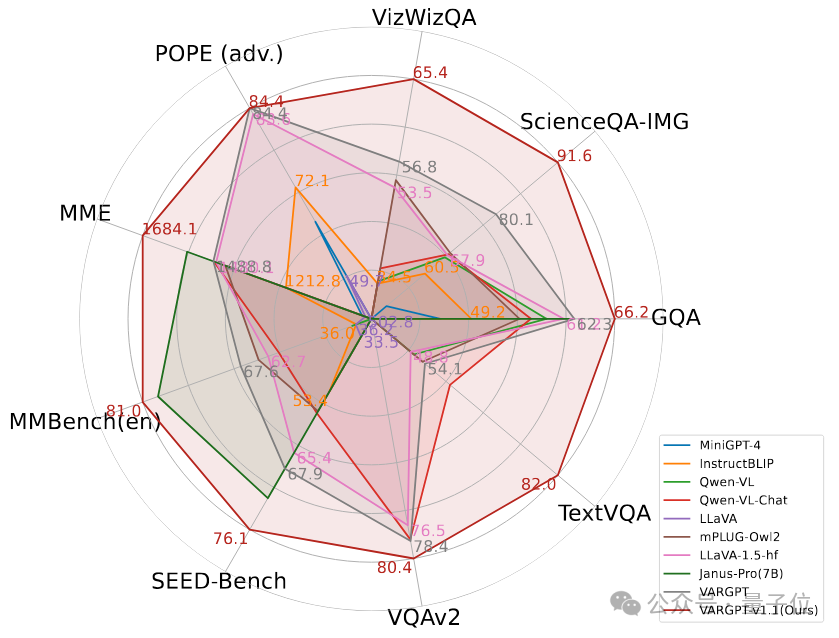
3.1 Zero-shot multi-modal evaluation
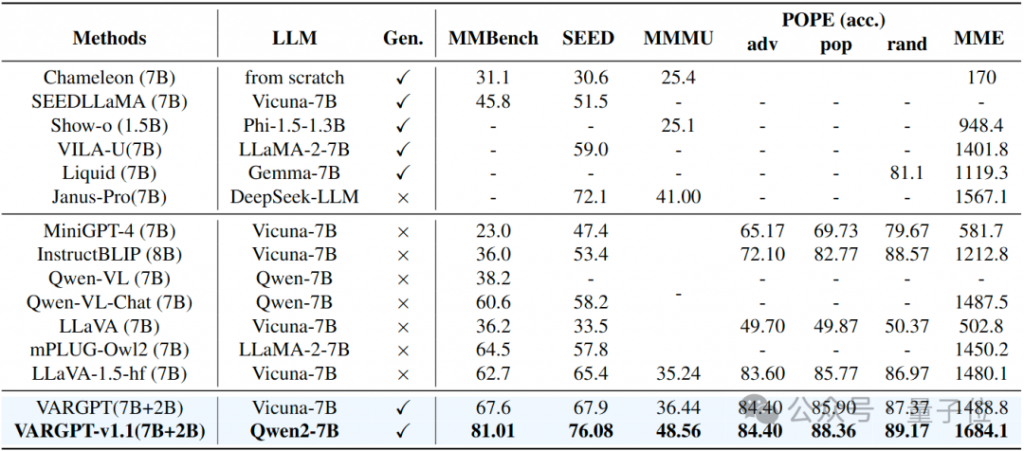
对VARGPT-v1.1与各种先进的多模态模型进行了全面评估,结果如下表。实验结果表明VARGPT -v1.1在所有基准测试中表现出色,在MMBench上达到81.01,在SEED上达到76.08,在MMMU上达到48.56,取得了先进水平的结果。此外,在LLaVA – Bench基准测试上的持续性能提升验证了我们的架构选择和训练策略的有效性,确立了VARGPT-v1.1作为一个强大且通用的多模态模型的地位。
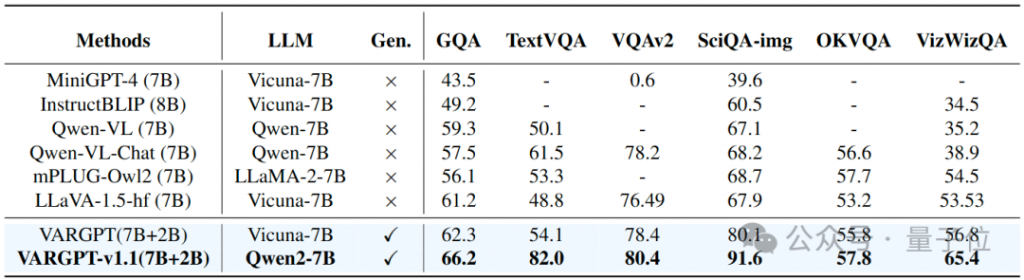
3.2 Performance comparison on visual question answering tasks
本文在多个视觉问答数据集上评估了VARGPT – v1.1的性能,并将其与几种最先进的多模态模型进行了比较。结果见表3。我们的实验结果表明VARGPT-v1.1在所有视觉问答(VQA)基准测试中均取得了卓越的性能,相较于现有模型有显著提升。
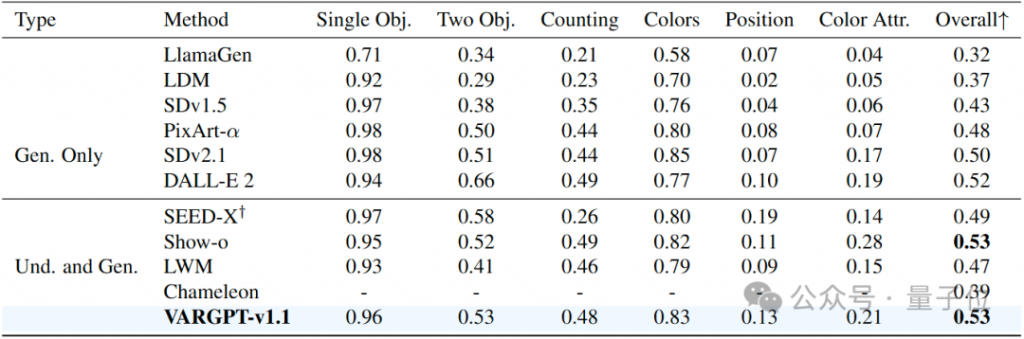
3.3 Performance comparison on visual question answering tasks.
为了评估VARGPT的视觉生成能力,我们使用广泛采用的GenEval基准和DPG – Bench基准进行了全面评估,定量结果分别见下表。这些数据集为文本到图像的生成能力提供了严格的评估框架。我们的实验结果表明,VARGPT-v1.1优于许多专门的图像生成模型,包括基于扩散的架构(如SDv2.1)和自回归方法(如LlamaGen)。
3.4 Performance comparison on the DPG-Bench benchmark.
3.5 视觉理解的比较
VARGPT-v1.1 展现了更强的理解和解读视觉内容中幽默元素的能力。

3.6 多模态图像文本生成
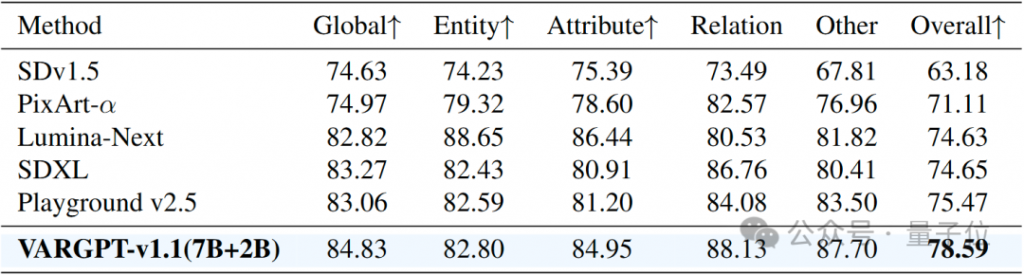
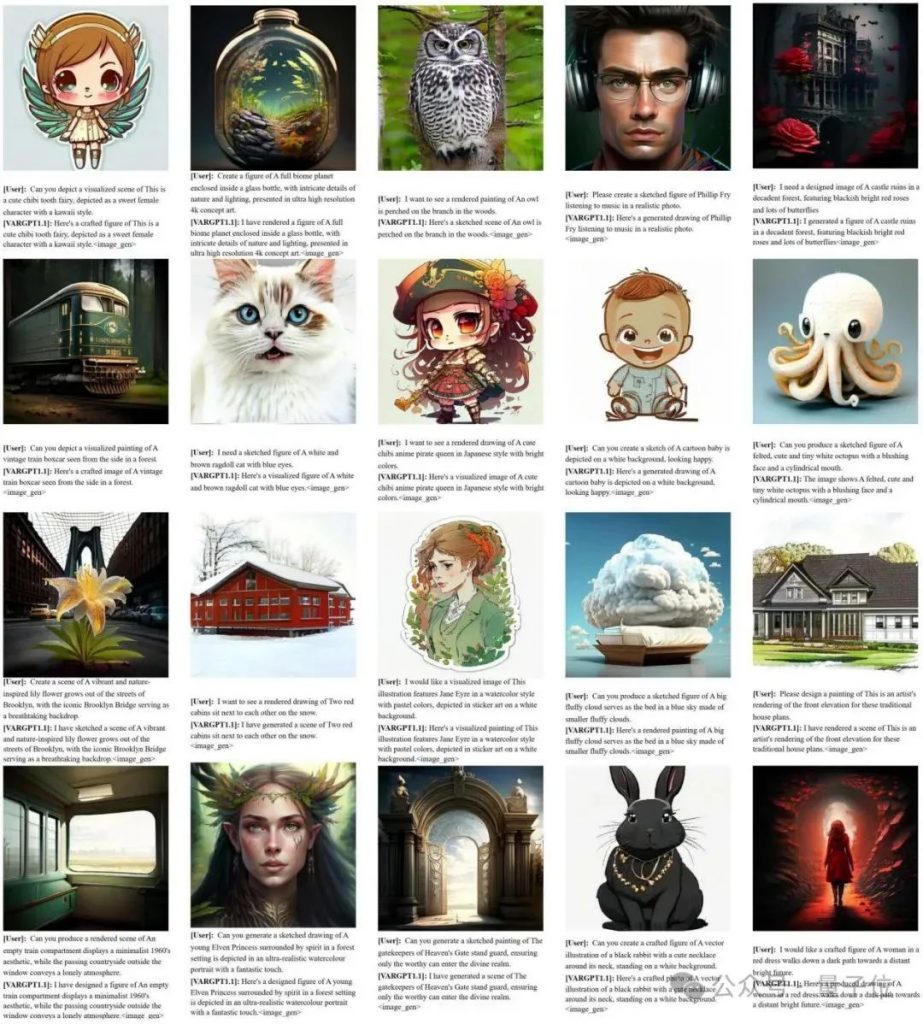
VARGPT-v1.1生成的一些512 x 512的样本如下所示。VARGPT-v1.1支持用户输入文本和图像指令,并同时输出文本和图像的混合模态数据。此外,与现有的统一模型基线相比,我们的方法在准确的文本到图像生成方面取得了显著改进。如下图所示,我们展示了VARGPT-v1.1生成的代表性图像输出和对话交互。定性分析表明,VARGPT-v1.1始终能生成与给定文本指令紧密匹配的高质量图像。
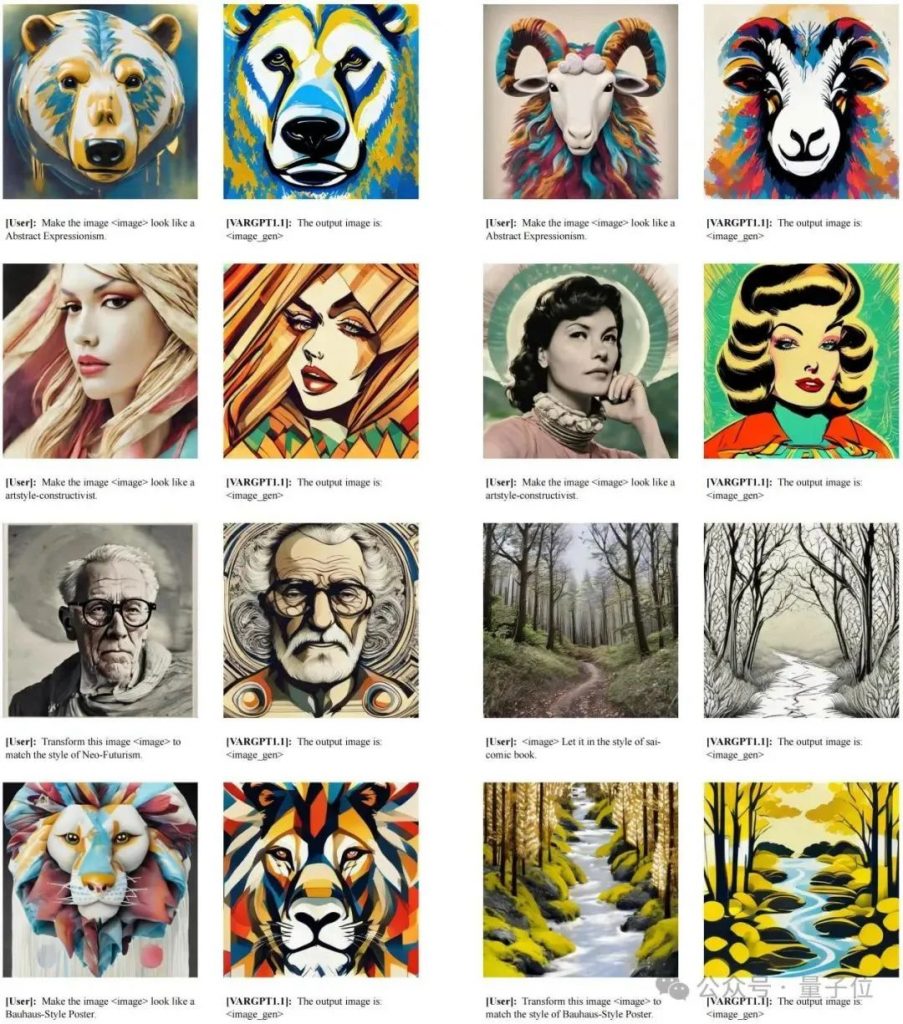
3.7 图像编辑能力
视觉编辑结果可视化如下图所示,本文对视觉编辑能力进行的定性评估表明,VARGPT-v1.1具备基本的图像操作能力。这种能力仅通过使用视觉编辑指令微调数据进行训练即可获得,无需对架构进行任何修改。此外,这些观察结果证实了统一模型架构在单一框架内实现通用视觉理解、生成和编辑方面具有巨大潜力。
4 结论与展望
VARGPT-v1.1通过采用为多模态大模型设计的灵活的训练策略使其具有可扩展性,同时为多模态系统架构设计开辟了新的技术途径。尽管VARGPT-v1.1取得了重大进展,但团队指出目前版本和商用生成模型之间仍存在差距,此外在图像编辑能力方面也存在局限性。未来,团队将进一步扩展训练数据规模,探索新型token化方法,并尝试更多的强化学习策略,进一步推动多模态生成理解统一大模型的发展。
project: https://vargpt1-1.github.io/
code: https://github.com/VARGPT-family/VARGPT-v1.1
arxiv: https://arxiv.org/abs/2504.02949
深圳市人工智能学会(Shenzhen Association for Artificial Intelligence,简称SAAI),是由深圳市人工智能科学与技术领域科技工作者和相关企事业单位自愿组成,依照国家有关法律法规登记的深圳市地方性、非营利性学术社团组织。中国科学院深圳先进技术研究院是SAAI理事长单位,北京大学深圳研究生院、清华大学深圳国际研究生院、哈尔滨工业大学(深圳)、南方科技大学、香港中文大学(深圳)、深圳大学、深圳技术大学、深圳职业技术大学、华为技术有限公司、深圳市腾讯计算机系统有限公司、中兴通讯股份有限公司等21个高等院校、科研机构和高新技术企业为SAAI副理事长单位。SAAI积极推动专业委员会和工作委员会建设,现已成立十一个专业委员会:1) 机器人智能系统专业委员会;2) 自然语言理解专业委员会(Natural Language Understanding Professional Committee);3) 智能金融专业委员会;4) 认知系统与智能信息处理专业委员会(Cognitive Systems & Intelligent Information Processing Professional Committee);5) 法律人工智能专业委员会;6) 智慧空间专业委员会;7) 元宇宙专业委员会;8) AI伦理治理专业委员会(AI Ethics Governance Professional Committee);9) AI红树林专业委员会(AI for Mangrove Professional Committee);10) 智慧海洋专业委员会(Intelligent Ocean Professional Committee);11) 大模型技术及应用专业委员会(Large Model Technology & Applications Professional Committee);12) 自动驾驶专业委员会(筹)。以及四个工作委员会:1) 女性AI科技工作者委员会(Women in Artificial Intelligence Committee,简称WAIC);2) 青年工作委员会;3) AI城市治理工作委员会;4) 财经人工智能工作委员会。
SAAI作为非营利之产学研政投的科技服务公共平台,旨在以“持续推进人工智能前沿基础理论和前沿技术研究”,以及“大力推动中国新兴产业的可持续发展”,面向国家科教兴国战略愿景,确立了“学术高地、引领知识、赋能产业”三大核心价值。SAAI全力打造了一系列专业品牌活动,包括:“深圳人工智能奖”、“信息科技女性精英论坛 (Women’s Elite Forum of Information Technology, 简称WeFIT)”、“人工智能科普基地”、“深圳市优秀科技学术论文遴选”、“SAAI -产学研政投沙龙”、“SAAI -博士论坛”、“SAAI -高质量科技探索营”、“SAAI -青年研享论坛”、和“SAAI -新兴产业智库”等。依托丰富的专业资源与人才优势,SAAI积极开展国内外学术交流、科学普及、专业培训、学术出版、人才推荐、学术评价、成果鉴定、评优评奖、专家咨询、建言献策以及科技会展等工作;加速推动深圳市和广东省人工智能科研成果产业转化,助力我国新兴产业升级与新质生产力提升,吸引世界各地的人工智能人才、技术与资源,向深圳及广东聚集,提升深圳市在全国以及全球人工智能领域的技术标准制定权和产业降本增效影响力。
| SAAI的三服务 | SAAI的三支持 |
| 服务支撑国家战略 服务助力创新知识和创新技术 服务粤港澳大湾区人工智能技术及应用的可持续发展 | 支持产学研政投的发展需求 支持会员个人的发展需求 支持会员单位的发展需求 |
 关注微信公众号
关注微信公众号