

在WeNet专区,我们可以了解到目前WeNet的最新成果并下载使用,也可以在文中的留言里发表你的看法和建议。
语音之家 – weNet专区
1.点击官网:http://www.speechhome.com(或在微信小程序搜索“语音之家”);
2.注册 语音之家 账号;
3.点击【声浪】→【weNet专区】。
端到端语音识别开源工具——WeNet,它同时支持流式及非流式识别,并能高效运行于云端及嵌入式端。
地址:https://github.com/mobvoi/wenet
WeNet工具和其核心算法U2(Unified Two Pass)的论文
WeNet :https://arxiv.org/pdf/2102.01547.pdf
U2 :https://arxiv.org/pdf/2012.05481.pdf
模型架构选择
WeNet中采用的U2模型,如下图所示,该模型使用Joint CTC/AED的结构,训练时使用CTC和Attention Loss联合优化,并且通过dynamic chunk的训练技巧,使Shared Encoder能够处理任意大小的chunk(即任意长度的语音片段)。

系统设计
为解决落地问题,同时兼顾简单、高效、易于产品化等的准则,WeNet做了如下图的三层系统设计。
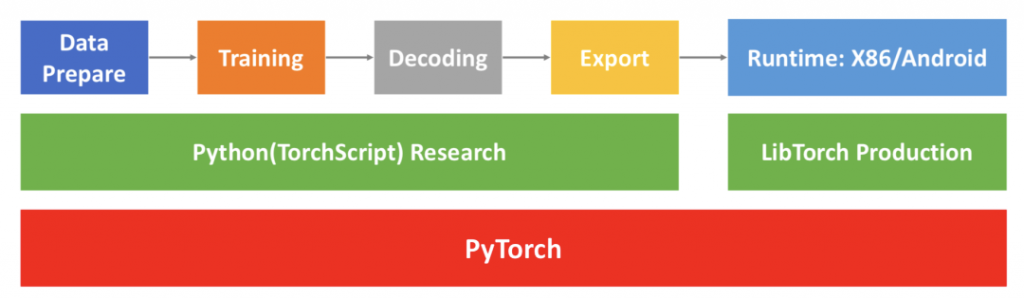
第一层为PyTorch及其生态。WeNet充分利用PyTorch及其生态以达到使用方便、设计简洁和易于产品化的目标。其中,TorchScript用于开发模型,Torchaudio用于on-the-fly的特征提取,DistributedDataParallel用于分布式训练,Torch JIT(Just In Time)用于模型导出,Pytorch Quantization用于模型量化,LibTorch用于产品模型的推理。
第二层分为研发和产品化两部分。模型研发阶段,WeNet使用TorchScript做模型开发,以保证实验模型能够正确的导出为产品模型。产品落地阶段,用LibTorch Production做模型的推理。
第三层是一个典型的研发模型到落地产品模型的工作流。其中:
- Data Prepare:数据准备部分,WeNet仅需要准备kaldi风格的wav列表文件和标注文件。
- Training:WeNet支持on-the-fly特征提取、CTC/AED联合训练和分布式训练。
- Decoding:支持python环境的模型性能评估,方便在正式部署前的模型调试工作。
- Export:研发模型直接导出为产品模型,同时支持导出float模型和量化int8模型。
- Runtime:WeNet中基于LibTorch提供了云端X86和嵌入式端Android的落地方案,并提供相关工具做准确率、实时率RTF(real time factor), 延时(latency)等产品级别指标的基准测试。
嵌入式端Android流式语音识别
WeNet中开发了嵌入式端Android平台的离线流式端到端语音识别,该示例中使用aishell训练的U2 transformer模型,并对模型进行8bit的量化。
详情请参考:
https://github.com/mobvoi/wenet/tree/main/runtime/device/android/wenet
云端X86流式语音识别
为模拟云端流式语音识别,WeNet中开发了基于WebSocket的流式方案,其中包含Server和Client两个部分,如视频演示了一次实时语音请求的过程,左侧为Server界面,右侧为Client界面。
详情请参考:
https://github.com/mobvoi/wenet/tree/main/runtime/server/x86
 关注微信公众号
关注微信公众号