
转自:雷锋网

预训练模型在自然语言处理和计算机视觉领域引起了学术界和工业界的广泛关注。利用大规模无监督数据进行训练的预训练模型有着非常好的泛化性,只需在小规模标注数据上进行微调,就可以在相应任务上有所提高。但相关研究的进展如何?还有哪些问题需要进一步探索?
2021年12月16日,北京大学深圳研究生院党委副书记、教授、博士生导师、北京大学现代信号与数据处理实验室主任邹月娴在中国计算机大会(CNCC 2021)“产业共话:大型预训练模型的商业应用及技术发展方向”论坛上,做了《视觉-语言预训练模型演进及应用》的报告,讨论了围绕大规模预训练模型的争议、最新进展以及研究思路,并给出了未来展望。
例如她提到:
“‘视觉-语言’的子任务非常多,有各自的数据集,这使得解决NLP任务的进展非常快,但预训练模型方法在视觉领域却遇到了非常大的问题:数据标记成本很高。MSCOCO数据集只标记了12万张图片,每张图片给出5个标记,总共花费了10.8W美金。”
“当前的几个主流VL-PTMs的技术路线很相似,都采用单一 Transformer架构建模视觉和文本输入;视觉输入为 Region-of- Interests (Rols) 或者 Patches,缺失全局或者其他高级视觉语义信息……”
而后者表明,主流视觉-语言预训练模型存在很多局限,导致在迁移至下游任务时,只适用于分类任务,而不适用生成任务。
以下是演讲全文,AI科技评论做了不改变原意的整理。
今天演讲的题目是《视觉-语言预训练模型演进及应用》,主要结合团队工作以及本人感悟探讨人工智能发展目前展现的趋势。本次演讲分为4个部分:背景介绍、视觉-语言预训练模型、视觉-语言预训练模型及应用研究以及未来展望。

人工智能已经有六十多年的发展历程,自2017年以来,Transformer和BERT(2018年)相继提出,开启了大数据、预训练与迁移学习新篇章,将其定义为新时代也毫不夸张。目前,不同于前几十年的工作已成定论,该领域尚待进一步深入探索。
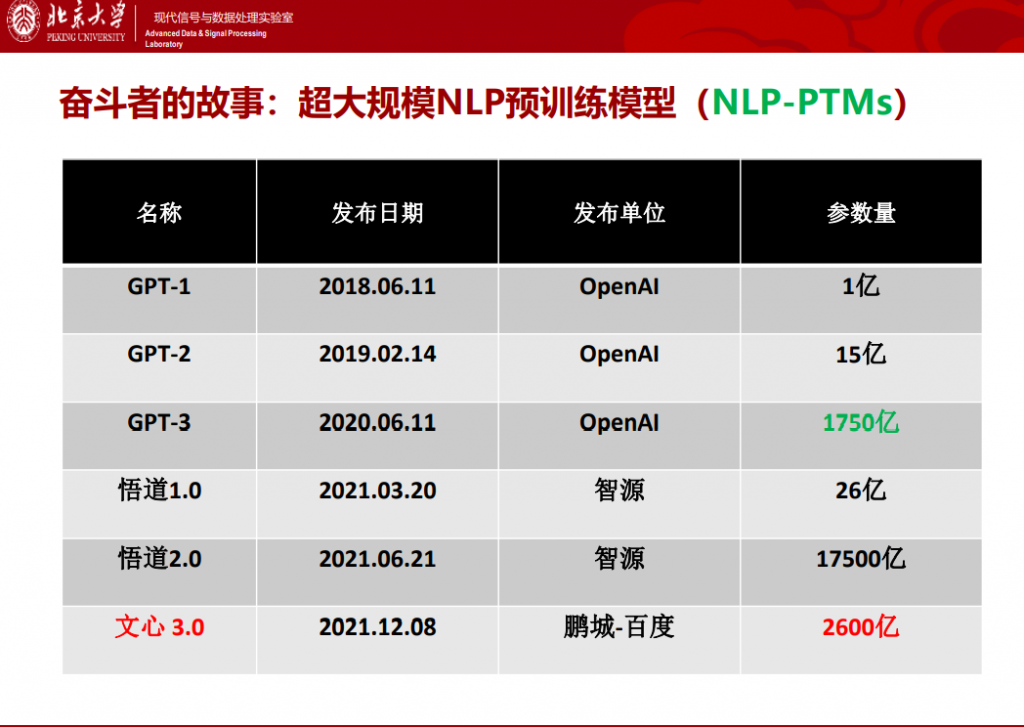
以自然语言处理(NLP)为例,其演化过程如上图所示,OpenAI在2018年发布第一代GPT模型,短短几年时间“大模型”已经初具规模。这里的“大”有两层含义:模型训练使用的数据量大,模型蕴含的参数规模大。中国在这方面也有出色的工作,2021年的悟道2.0更是达到了万亿参数规模。
目前关于大规模预训练模型还有一些争议,主要的争论点在于:
1.超大模型学到了什么?如何验证?
2.如何从超大模型迁移“知识”,提升下游任务的性能?
3.更好的预训练任务设计、模型架构设计和训练方法?
4.选择单模态预训练模型还是多模态训练模型?
虽然有争议,但不得不承认 “暴力美学”确实有独到之处,例如百度ERNIE3.0曾经刷新了50多个NLP任务基准。要知道,在业界,无数学生、学者为一个SOTA就绞尽脑汁了,但大规模预训练模型却能批量“生产”SOTA。另一方面,50多个SOTA也说明,这不是偶然。
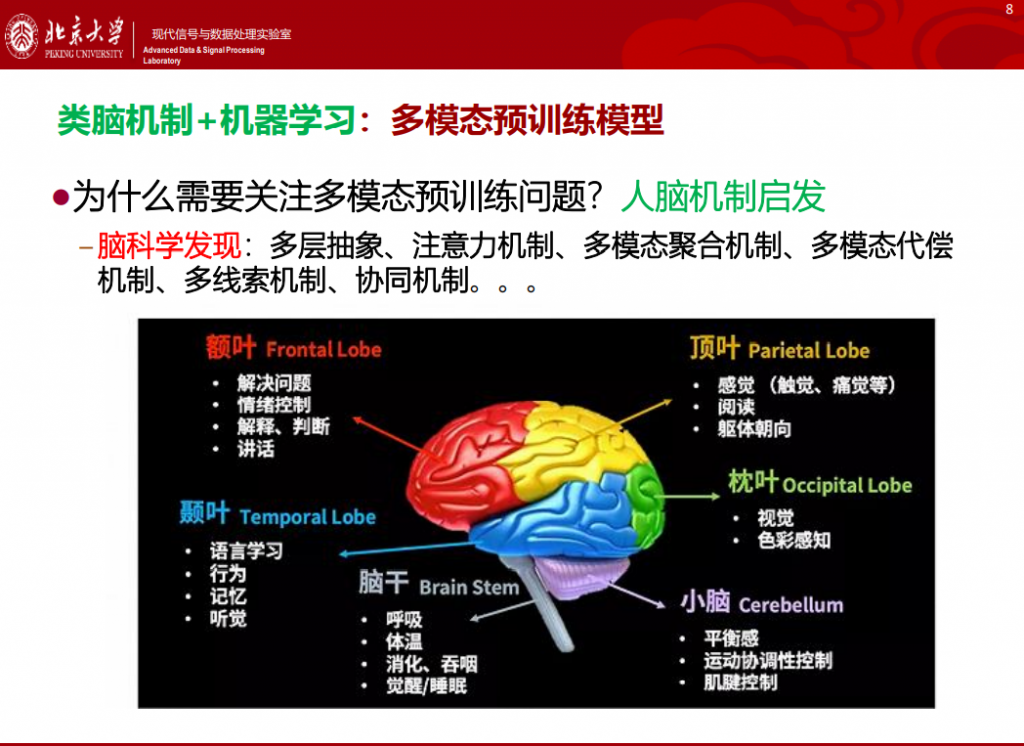
目前学界已经公认AI的发展离不开借鉴人类大脑的研究成果,因此多模态预训练模型这条集成类脑机制和机器学习的路径,自然也成为关注的焦点。
但仍然有许多脑科学发现的机理未能弄清楚,例如多层抽象、注意力机制、多模态聚合机制、多模态代偿机制、多线索机制、协同机制等等。
人类约有70%的信息依靠视觉获得,剩余约20%~30%的信息依靠听觉和触觉。关于人类智能,语言具备真正高阶的语义。例如,当说到“苹果”一词的时候,脑子 “浮现”的是一张“可以吃”的苹果图片;当说到 “苹果手机”的时候,大脑则会出现苹果牌手机的概念。
因此,大脑这种“视觉参与听觉感知”的机制、“视觉概念与语言概念一致性”的认知机制是我们机器学习采取多模态预训练模型的可靠性依据之一。
“视觉-语言模型”开发是否可行?中国人民大学的一项研究表明,互联网提供了90%的图文大数据,而文本数据只占了10%。在大量数据源的加持下,视觉-语言预训练模型也成了2021年的研究热点。
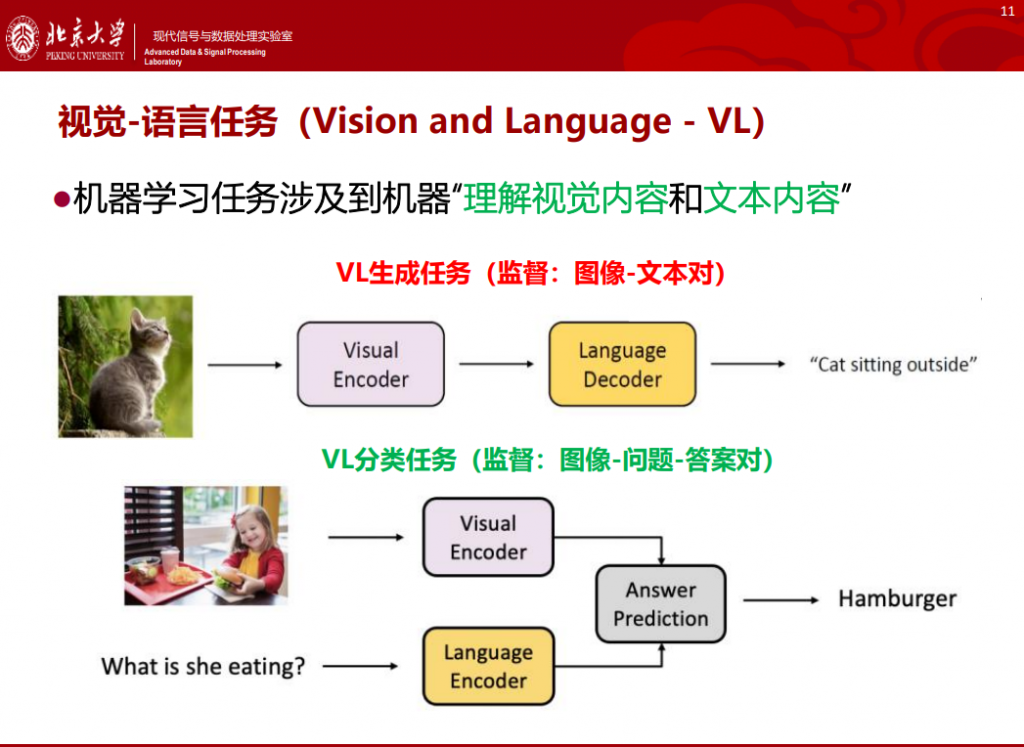
视觉-语言,英文名称是“Vision and Language,VL”。VL预训练模型旨在让机器处理涉及到“理解视觉内容和文本内容”的任务。VL任务可以分成VL生成任务和VL分类任务。
这两类任务解决的问题不一样,难度也不一样。对于VL生成任务,不仅需要对视觉信息进行理解,还需要生成相应的语言描述,既涉及编码,又涉及解码;而VL分类任务只需要理解信息。显然,生成任务的难度较大。

VL生成任务的技术难点在于需要理解视觉的高阶语义,建立视觉-文本的语义关联。例如,视频描述(Video Captioning)任务需要“概括”视频内容,图像描述(Image Captioning)任务需要对每一帧图像生成描述。
目前,视觉问答(VQA)是热门的VL分类任务之一,可以理解为:给定一张图像,让模型回答任何形式的基于自然语言的问题。

如上(左)图所示,如果你询问机器“What is she eating?”,VL分类器就会理解图片信息,然后给出正确的回答“hamburger”。
当前“视觉-语言”的子任务非常多,各有数据集,例如VQA、VCR、NLVR2等等。我们注意到,由于NLP任务有大数据集支持,其预训练模型技术发展迅猛。但对于视觉-语言任务,由于标注大规模数据集需要极高的成本,导致VL模型的性能提升缓慢。
以图像描述任务为例,MSCOCO数据集只标记了12万张图片,每张图片给出5个标记,总共花费了10.8W美金。因此,不同的VL任务依赖于不同的模型框架+不同的标注数据集,标注代价昂贵,性能尚未满足应用需求。
因此,探索新的VL预训练代理任务,减少对数标注的依赖,是一个很有意义的研究方向。2019年学术界开启了VL-PTMs的研究工作。
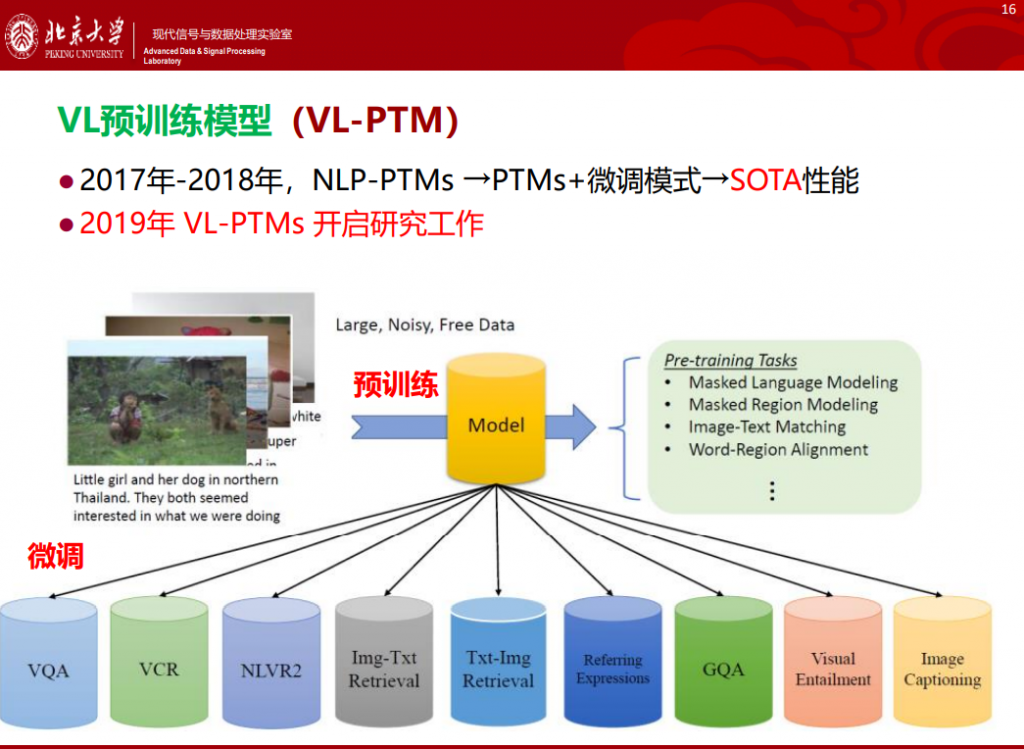
视觉-语言预训练模型的演进
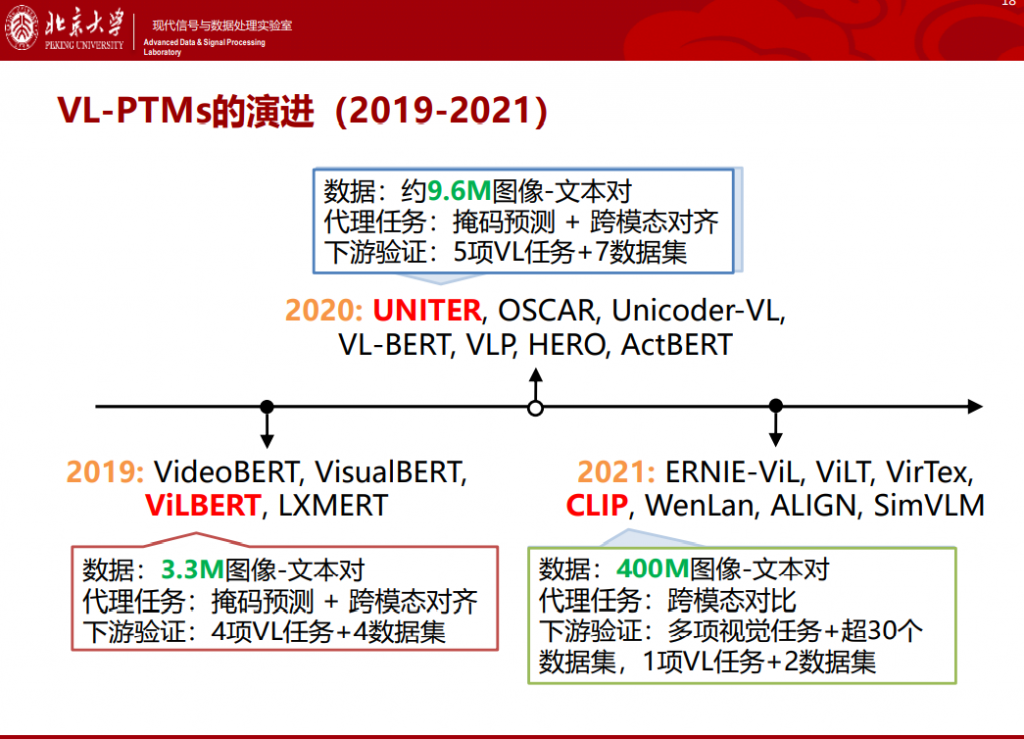
关于VL预训练模型,从2019年开始就出现了非常多的出色工作,例如“开山”的ViLBERT,2020年的UNITER以及2021年的CLIP。随着时间的推移,模型包含的数据量也越来越大,能力越来越“出众”。整体的技术路线可以分为两大类:单塔模型和双塔模型。
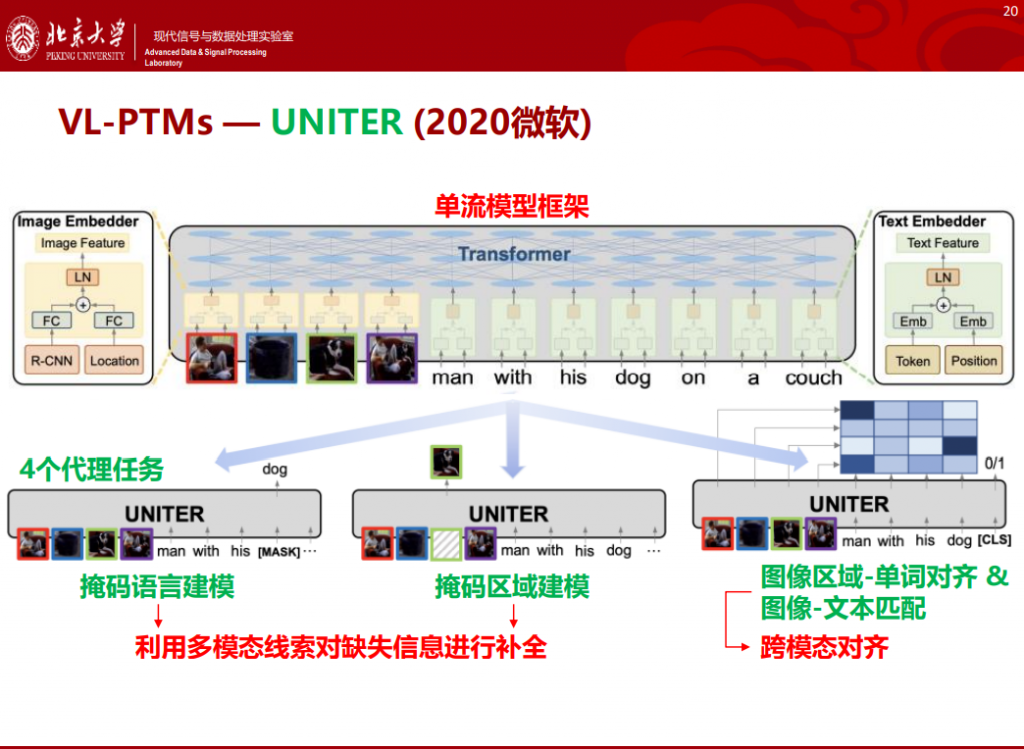
UNITER是2020年由微软提出的,它用了4个代理任务训练模型,在4个下游任务进行了测试,获得了性能提升。上述研究都是采用预训练模型加 “微调”的研究范式。
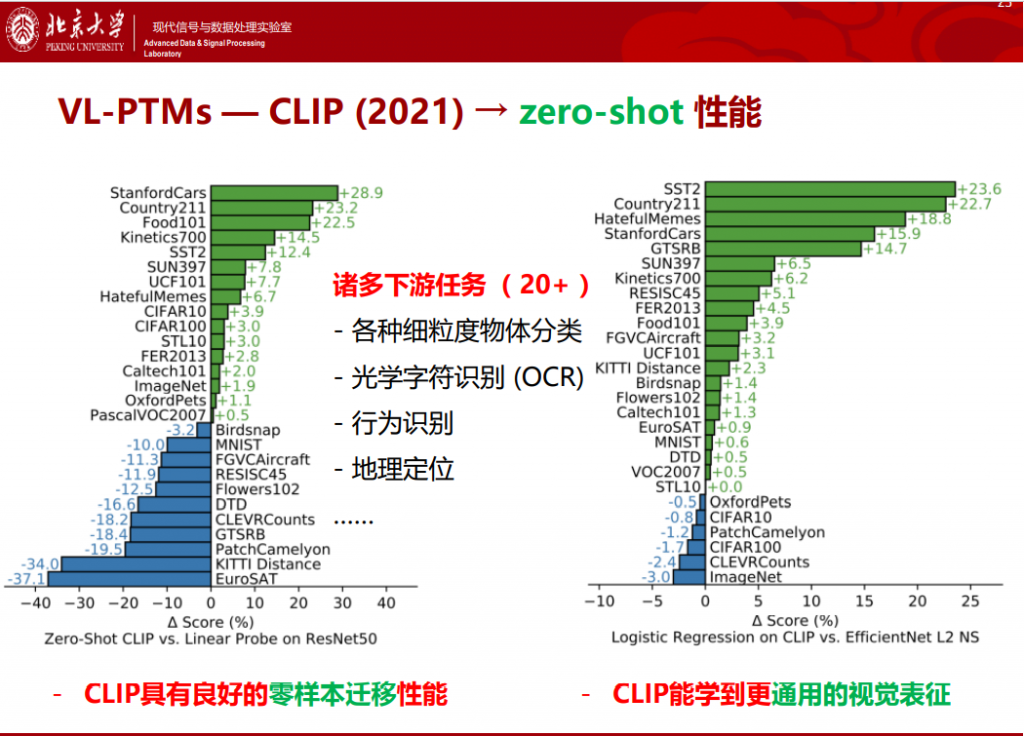
2021年OpenAI用双流框架开发了CLIP,CLIP的出现就技惊四座。其原理非常简单,分为编码和解码两个部分,编码器选用典型的Transformer。CLIP模型的惊艳之处在于,CLIP预训练模型直接能够拥有零样本学习(Zero-Shot Learning)能力, OpenAI在20多个不同粒度的分类任务中测试发现,CLIP预训练模型具有良好的零样本迁移性能,能学到更通用的视觉表征。
视觉-语言预训练模型及应用研究
我们对上述主流VL预训练模型,从基础网络结构、视觉输入、文本输入、主流数据集、训练策略以及下游任务六个方面进行了分析。

分析发现,主流VL-PTMs的技术路线很相似:
1. 采用单一Transformer架构建模视觉和文本输入;
2. 视觉输入为 Region-of- Interests(Rols)或者 Patches,缺失全局或者其他高级视觉语义信息;
3.大多采用的代理任务是BLM(双向语言模型)、S2SLM(单向语言模型)、ISPR(图文匹配)、MOP(掩蔽物体预测)等等。
因此,已提出的视觉-语言预训练模型更适合迁移到下游分类任务,例如VQA。对于下游生成任务,例如图像描述,视觉-语言预训练模型并不适合。
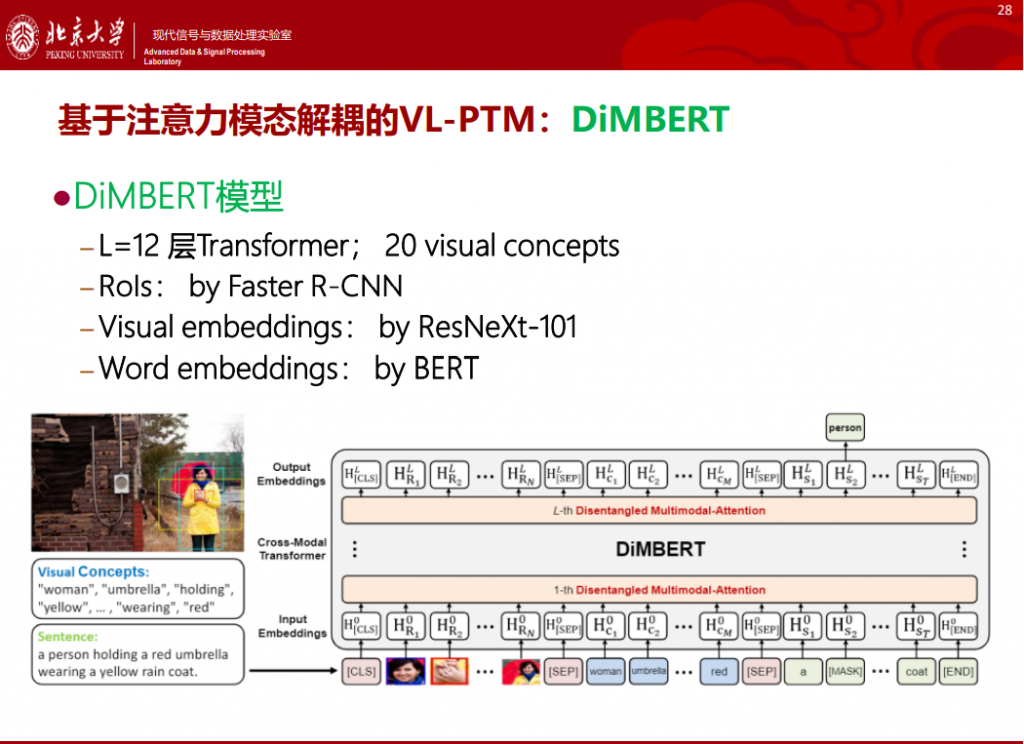
我们团队也开展了探索性研究,研究思路是堆叠Transformer+自注意力机制,其中创新地提出自注意力模型区别地处理视觉模态和文本模态,即采用不同的QKV变换参数,分别对视觉和文本模态建模。
同时,引入视觉概念信息,缓解视觉语义鸿沟。经过验证发现,我们提出的基于注意力模态解耦的VL-PTM: DIMBERT(2020),可以同时适用于分类任务和生成任务。
相比当年(2020年)的最新SOTA, DIMBERT模型更小(隐形双塔),仅仅在 Conceptual Captions任务上进行预训练,具有数据量需求优势,在测试的下游任务都达到SOTA,在没有decoder的架构下,可以迁移至下游生成任务。
这项工作也给我们两点启示:
1.从信息表征视角来看,视觉信息和文本信息需要不同的表达方法,毕竟文本拥有相对更加高阶的语义信息。
2.尽量引入人类高阶语义信息,人类对物体有非常明确的定义,苹果就是苹果,梨就是梨,因此定义物体属性,用语言信息缓解语义鸿沟非常有必要。

2021年10月份,Facebook发布了Video CLIP相关工作,属于视频VL预训练模型。从这个模型可以看出,Video CLIP颇具野心,期待对于下游任务不需要任务相关训练数据集,不需要进行微调,直接基于Video CLIP进行零样本迁移。
具体而言,它基于对比学习结合Transformer框架,试图搭建视觉-文本联合预训练模型,期望能够关注更细粒度的结构。
Video CLIP的核心工作聚焦于对比学习框架结合训练数据样本的构造,其正样本的构造是视频段-匹配文本描述对。此外,通过对正样本进行近邻搜索,获得困难负样本,从而构建出视频-非匹配文本对。
更为具体,该模型采用对比损失,学习匹配视频-文本对之间的细粒度相似性;通过对比学习方式拉近具有相似语义的视频-文本表征。这个工作从研究的创新性来看并不突出,但模型性能令人惊讶。
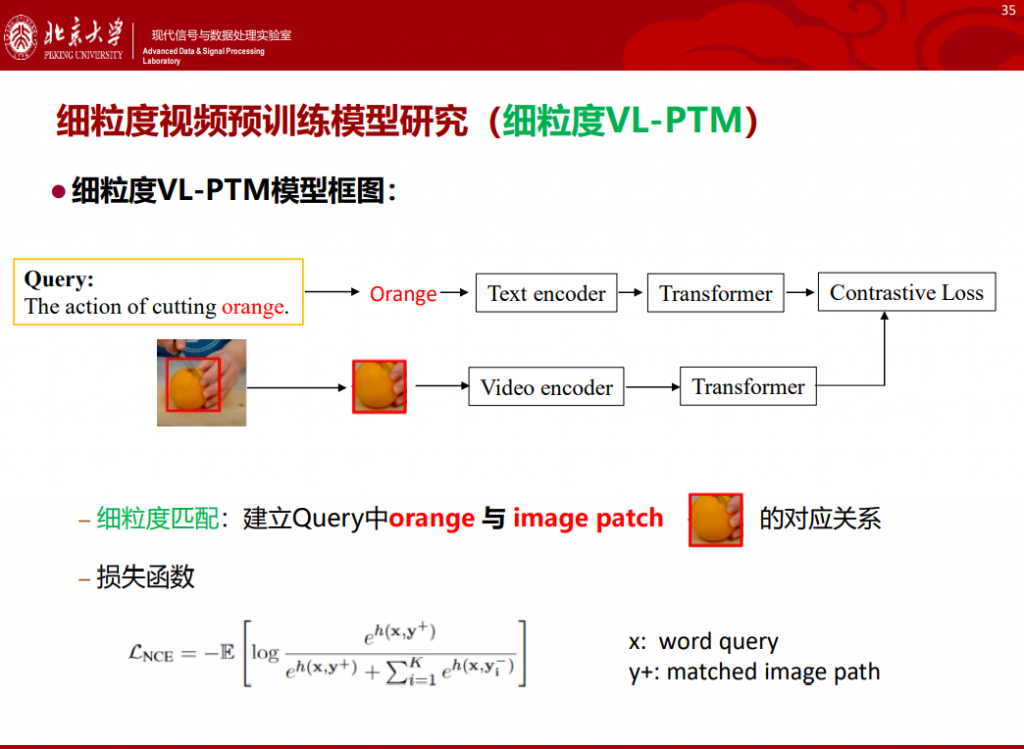
我们认为,借鉴Video CLIP的研究思路,可以在更细粒度层面进行提升,我们提出了一个帧级别文本细粒度匹配方法。
实验结果表明,细粒度匹配能获得更加准确、具有完整的空间建模能力。我们在 ActivityNet数据集上进行了视频检索的召回率测试,发现在所有 epoch下,我们提出的基于细粒度匹配策略的预训练模型性能都优于基于全局匹配策略的预训练模型;此外,我们发现,当获得同一性能,我们提出的基于细粒度匹配的模型其训练速度是基于全局匹配方法的四倍。
综上,预训练模型、跨模态预训练模型方面的研究是非常值得探索的,无论是模型结构、训练策略还是预训练任务的设计都尚有非常大的潜力。
未来,AI社区或许会探索更多的模态,例如多语言、运动、音频以及文字;更多的下游任务,例如视频描述、视频摘要;更多的迁移学习机制,例如参数迁移、提示学习、知识迁移等等。
 关注微信公众号
关注微信公众号